-a3b98c055c9d745cb7d924f8be484176.jpg)
En science des données, il existe un processus couramment utilisé appelé Extract-Transform-Load (ETL). L'ETL comprend trois étapes principales :
- Extraire des données d'une source,
- Transformer les données via le nettoyage et la manipulation des données, et
- Charger les données transformées dans un entrepôt de données (la collection finale de données) (Sethi, 2018)
Avant d'avoir beaucoup d'expérience dans le traitement des données, mon collègue Devon et moi n'étions pas sûrs de ce qu'était ETL. Maintenant, après avoir transformé conjointement un ensemble de données entier à partir de XML à une toute nouvelle structure utilisant triples utilisant CIDOC CRM, on commence à comprendre le processus...
Pour la majeure partie du processus de transformation, nous avons utilisé l'outil Mapping Memory Manager (3M), car il a effectué la plupart des transformations dont nous avions besoin dès le départ.
Pourquoi utiliser un pipeline ETL ?
La première question est pourquoi avons-nous besoin d'utiliser un processus ETL sur nos données ? Dans notre cas, LINCS travaille avec de nombreux ensembles de données dans de nombreux formats différents, y compris des données relationnelles, des TSV, XML et autres, chacun structuré selon les conventions des chercheurs fournissant les données. En particulier, pour notre tâche, nous avions besoin de convertir des données XML, formatées selon la spécification Yellow Nineties, vers CIDOC CRM, afin d'avoir à terme un modèle de données commun avec vocabulaires qui sont liés. Cela fait, les chercheurs pourront apprendre de nouvelles choses à partir des ensembles de données connectés. Dans l'article de blog [« Pourquoi LINCS ? mêmes termes, et peut faire progresser les connaissances et le débat sur ces choses en collaboration. »
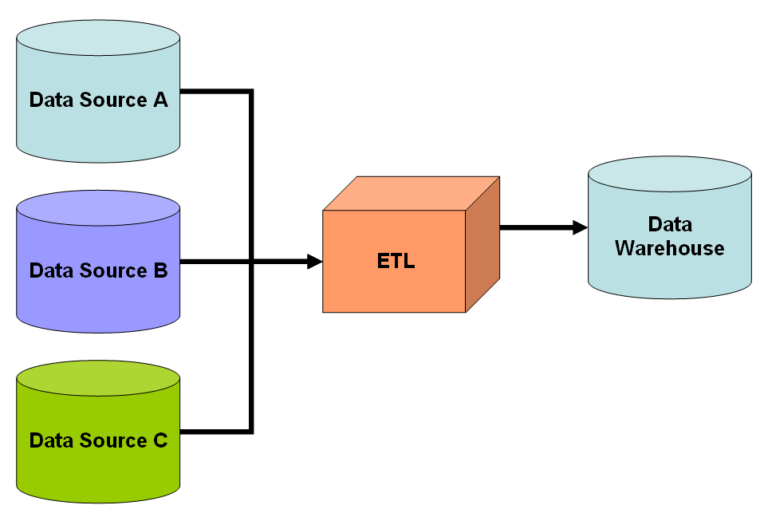
Comment démarrez-vous un pipeline ETL ?
On pourrait écrire une pile logicielle entière pour effectuer le travail de transformation, mais le plus souvent (en particulier sur les projets open source), la première étape consiste à rechercher un outil existant. Cela nécessite beaucoup plus de recherches que ce que l'on pourrait imaginer au départ. Quelques questions clés à poser lors de la recherche d'outils sont :
- L'outil fera-t-il exactement ce dont vous avez besoin ? Sinon, pouvez-vous le modifier pour faire cela?
- Dans quelle langue l'outil est-il écrit ? A-t-il une interface utilisateur frontale simple ?
- Existe-t-il une documentation solide sur l'utilisation de l'outil ?
- Sa licence correspond-elle à vos besoins ? Est-il activement entretenu et/ou surveillé ?
Pour la plupart, 3M a répondu oui à toutes ces questions pour LINCS. Il a été capable de transformer un ensemble de données complet de XML en CIDOC CRM, presque dès la sortie de la boîte.
De quoi un pipeline ETL est-il capable ?
Les avantages du développement d'un pipeline ETL sont similaires aux avantages de la programmation orientée objet (POO). Avec 3M, dès que nous avons modifié les données d'entrée, la sortie est automatiquement mise à jour. Cela signifiait que nous pouvions facilement configurer de nombreux aspects du processus de transformation. Par exemple, une modification peut changer le modèle des étiquettes générées automatiquement, ce qui signifie que nous pouvons facilement transformer l'ensemble de données complet avec de nouvelles étiquettes. Le front-end de 3M a une couche d'abstraction où le fonctionnement interne est caché, ce qui en fait un outil facile à comprendre pour nous.
Considérations finales
3M n'était pas en mesure de faire tout ce dont nous avions besoin, donc dans certains cas, nous avons écrit notre propre code pour transformer nos données avant de les charger dans 3M. En particulier, 3M ne pouvait extraire des informations que d'un l'ensemble de triplets de l'entité> à la fois, nous devions donc utiliser XPATH pour ajouter des informations à une entité en utilisant les informations d'une autre. Lors de l'écriture de ce code, nous avons dû garder à l'esprit un autre concept de base d'un pipeline ETL : l'évolutivité. L'ensemble de données que nous avons converti n'est pas le seul ensemble de données XML qui sera converti, ce qui signifie que l'ensemble du processus doit être capable de transformer de nouvelles données sans apporter de modifications sérieuses.
En suivant certains des concepts de base d'un pipeline ETL, nous espérons avoir rendu la préparation des données pour ce chargement final aussi automatisée que possible et donc plus facile pour les futurs chercheurs.
Dans un autre article de blog, Devon explique comment 3M relève les défis liés à la main-d'œuvre impliquée dans le processus de conversion des données.
Ouvrages cités
Sethi, Diljet Singh. "Comprendre l'extraction, la transformation et le chargement (ETL) dans le monde de l'analyse de données avec un exemple en code Python." Investisseur axé sur les données. 8 juillet 2018. https://medium.datadriveninvestor.com/understanding-extract-transform-and-load-etl-and-its-necessity-in-data-analytics-world-with-an-64346016153d.